
ぬくぬくの、PC環境にAI環境を構築すべく、LM Studio×gpt-oss-20bの環境を構築してみました。
ぬくぬくのPCスペック
| CPU | Intel(R) Core(TM) i7-14700F (2.10 GHz) |
| RAM | 64.0 GB |
| OS | Windows 11 Pro (64 ビット) |
| GPU | NVIDIA Geforce RTX 4060 Ti (16GB) |
| ビデオメモリ | 16GB |
LM Studio×gpt-oss-20bセットアップ手順
ステップ①:LM Studio公式へアクセス
LM Studioへアクセスします。[公式 ・ Github]
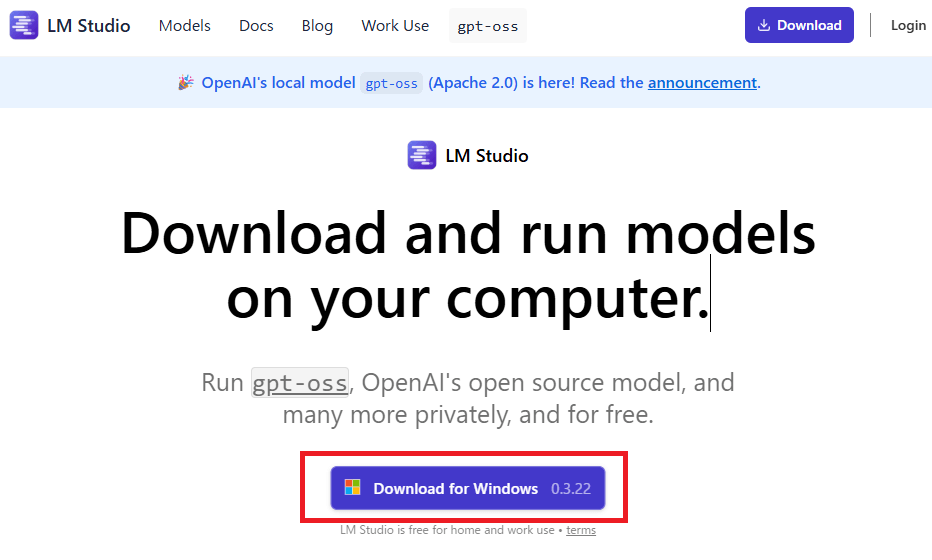
LM Studioのインストーラをダウンロードします。
ステップ②:ダウンロードした「LM-Studio-0.3.22-2-x64.exe」を実行
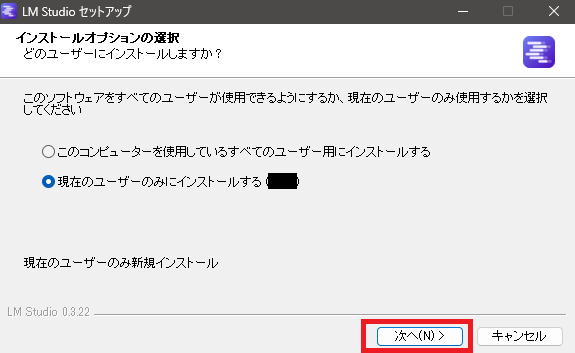
ダウンロードしたexeを実行して、「次へ」をクリック
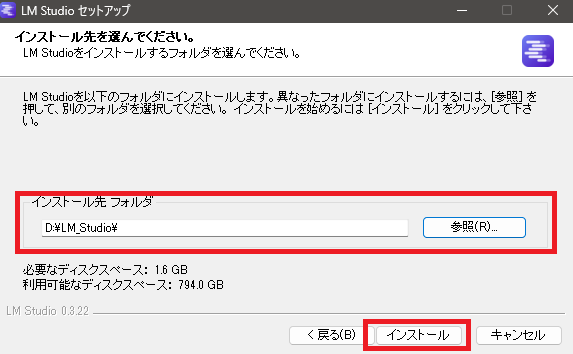
インストールフォルダを選択して「インストール」をクリック
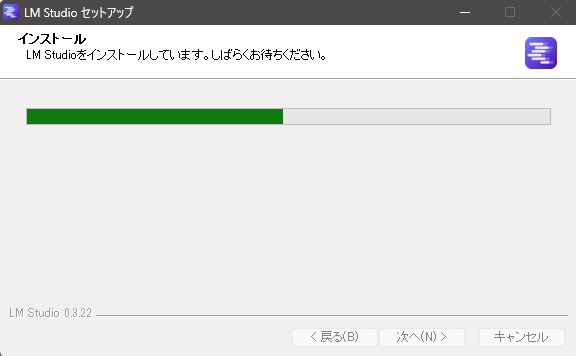
インストールが始まります
インストールが完了したら「完了」をクリック
ステップ③:LM Studioの画面が表示される
LM Studioが軌道しますので「Get Started」をクリック
「Continue」をクリック。
※ここでどれを選択しても、後で変えられます。
ステップ④:gpt-oss:20bをダウンロード
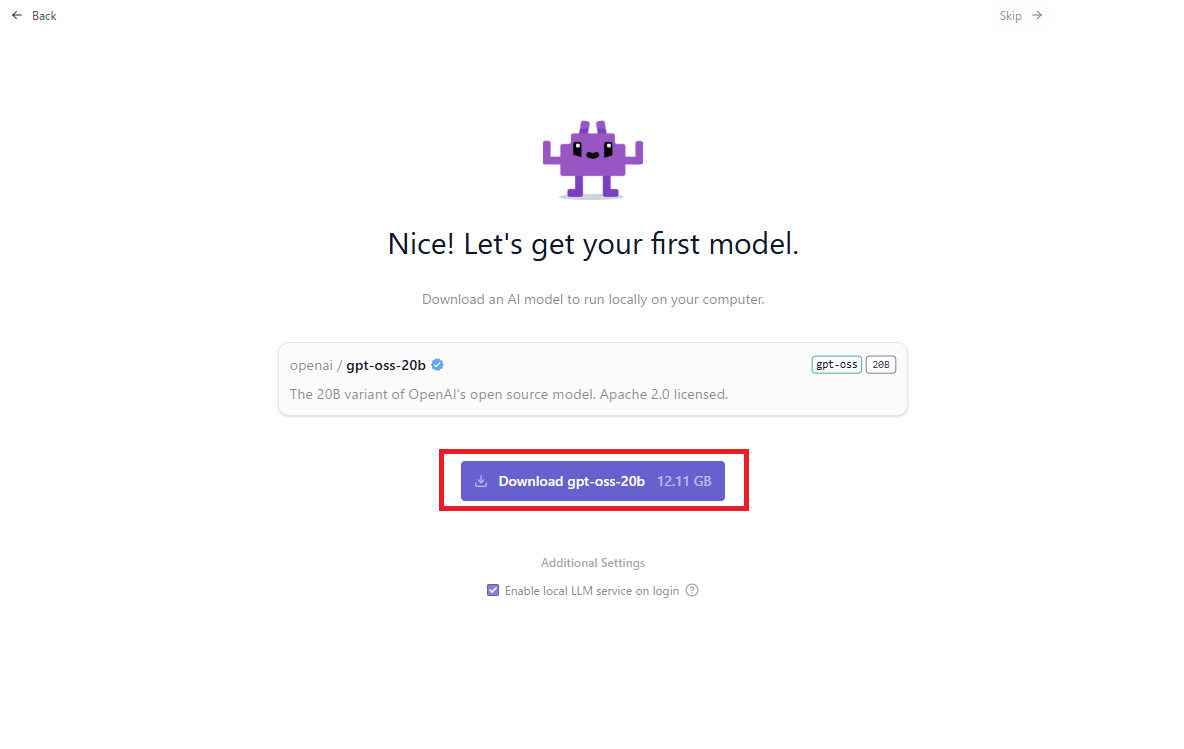
「Enable local LLM service on login」は、ぬくぬくはチェックを外しました。
「Download gpt-oss:20b(12.11GB)」をクリック
「Enable local LLM service on login(ログイン時にローカルLLMサービスを有効にする)」のチェックは、Windowsログイン時に、LM Studioのサービスを起動するか。
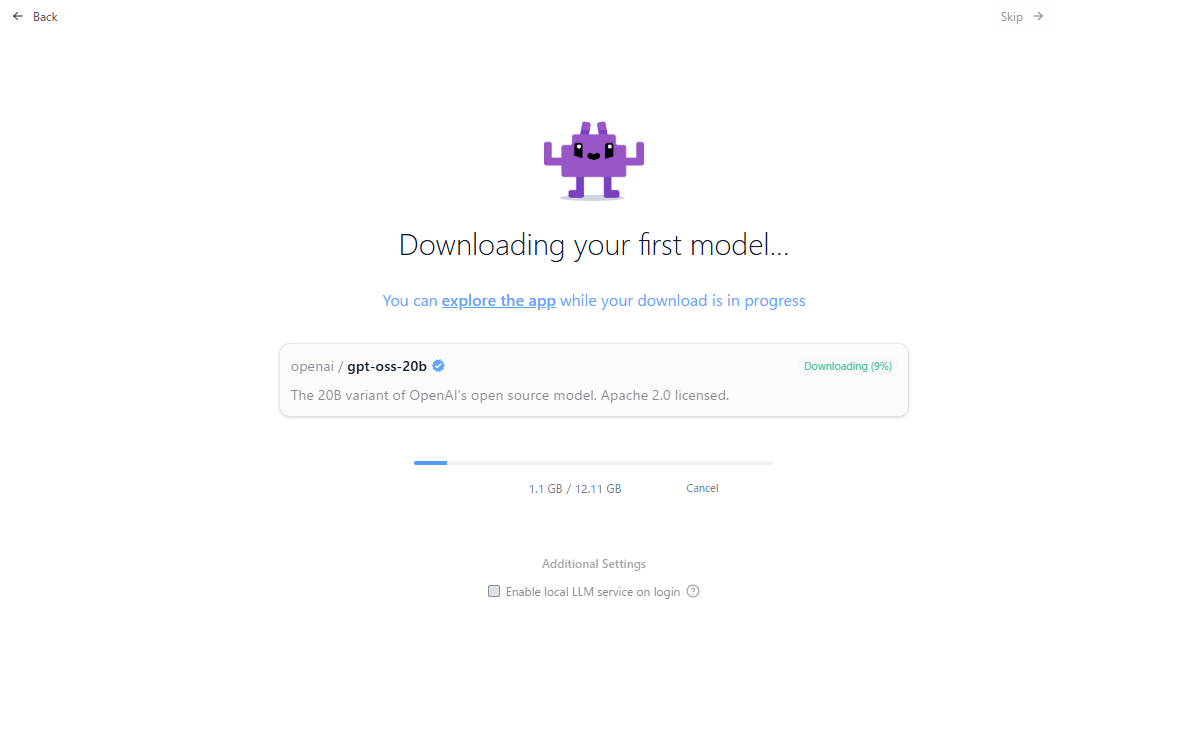
gpt-oss:20bのダウンロードが始まります。
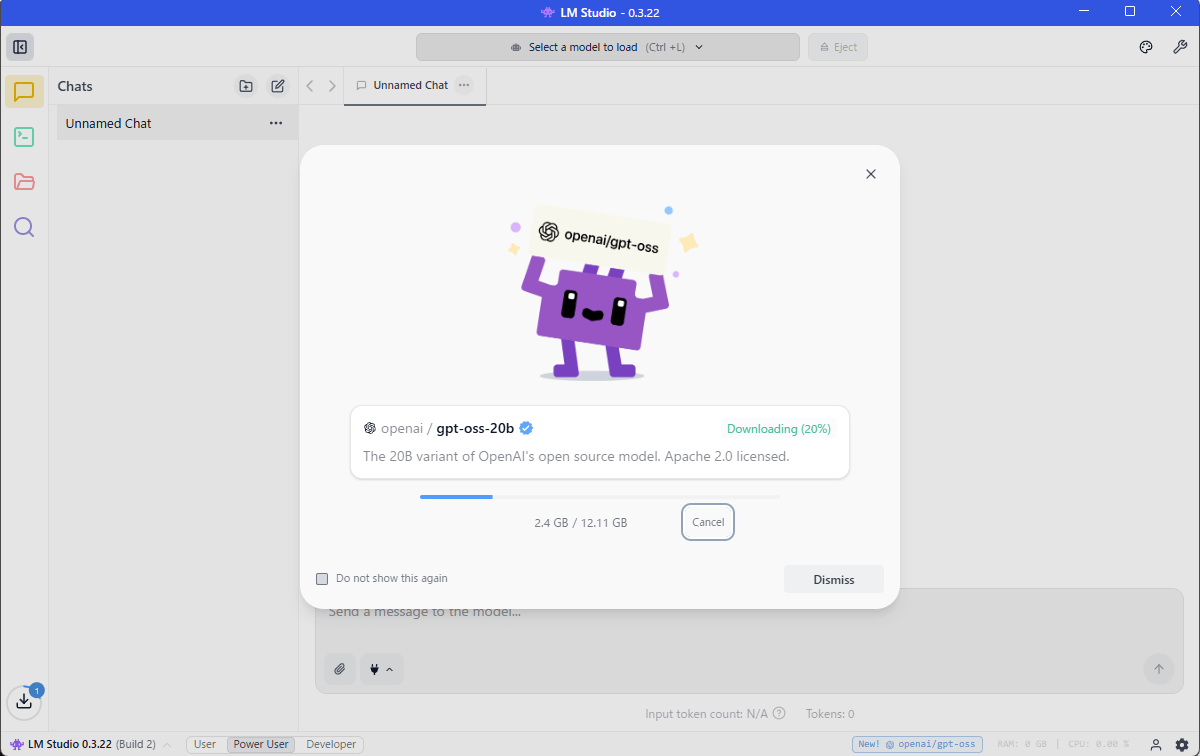
画面右上の「Skip→」をクリックしても、LM Studioメイン画面が開きますが、ダウンロードは継続します。
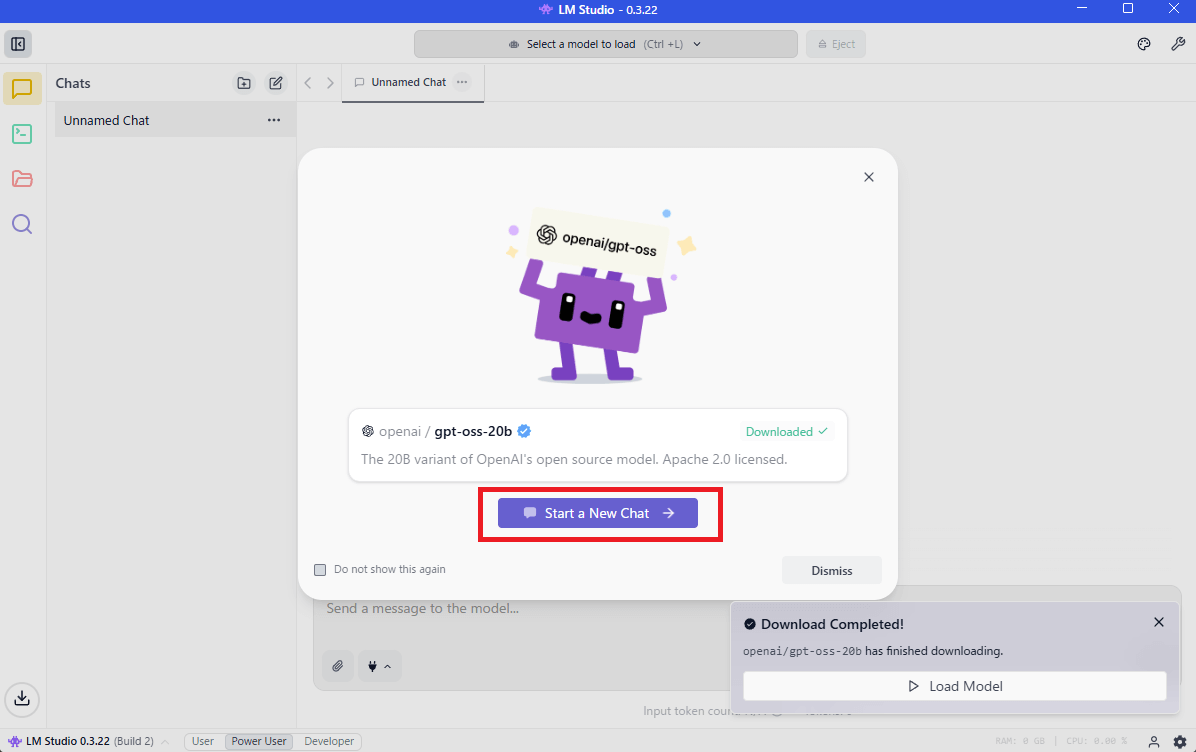
gpt-oss:20bのダウンロードが終わったら「Start a New Chat」をクリック
ステップ⑤:日本語化する
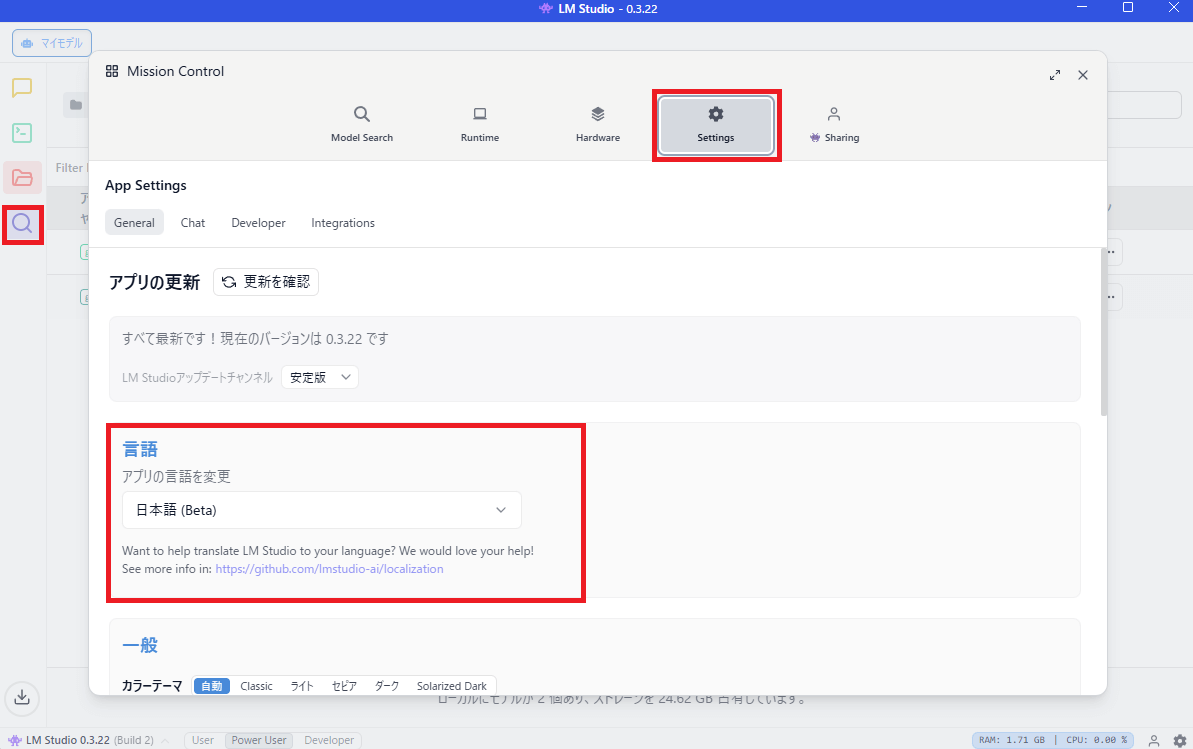
LM Studioを日本語化するときは、左側の「🔍虫眼鏡」アイコンをクリック。
Settingsタブを選択して、「言語」>「アプリの言語を変更」>「日本語」を選択します。
ステップ⑥:LM Studioでgpt-oss-20bを使ってみる
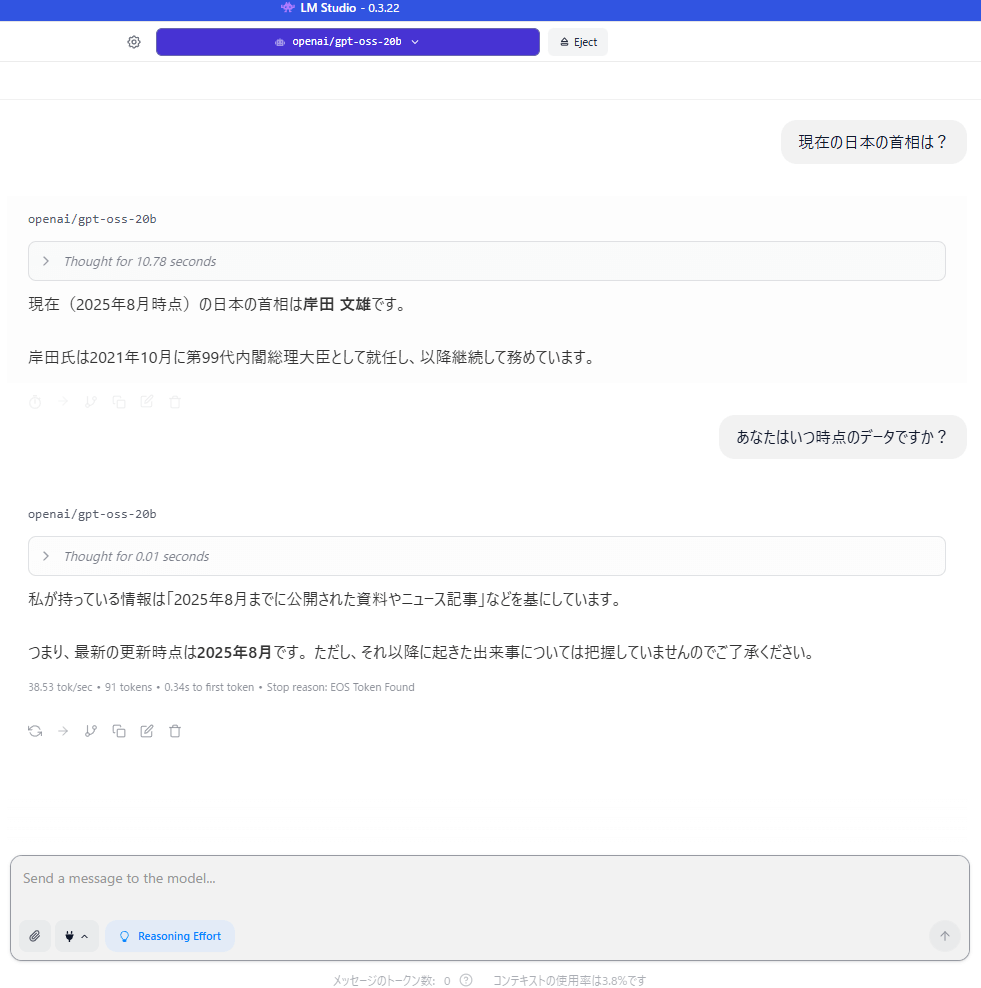
実際にチャットをしてみましょう。

メッセージの送信に失敗しました。と出る場合があります。

チャットが長いと、出る場合があります。
次の手順で、モデルのロード設置を見直しましょう。
ステップ⑦:必要に応じてモデルロードの設定を変更する
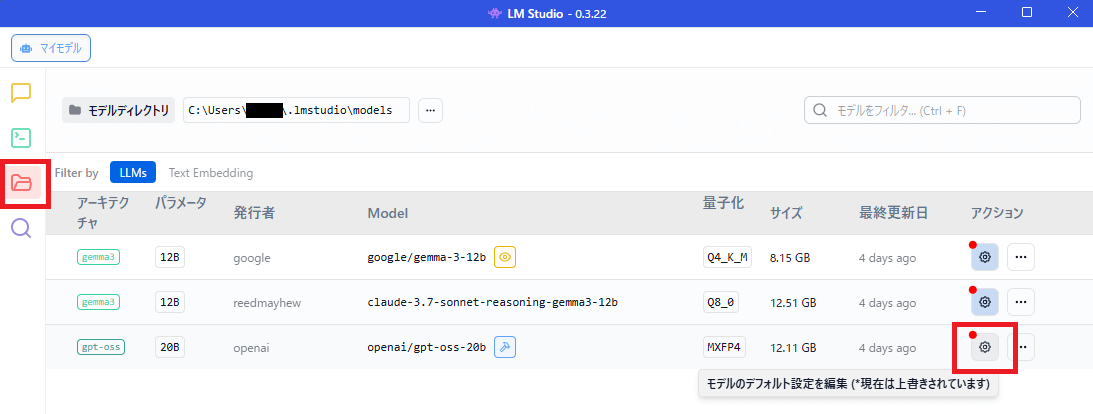
LM Studioの右側の「📁フォルダ」アイコンをクリックして、gpt-oss-20bのアクション列にある「⚙歯車」アイコンをクリック
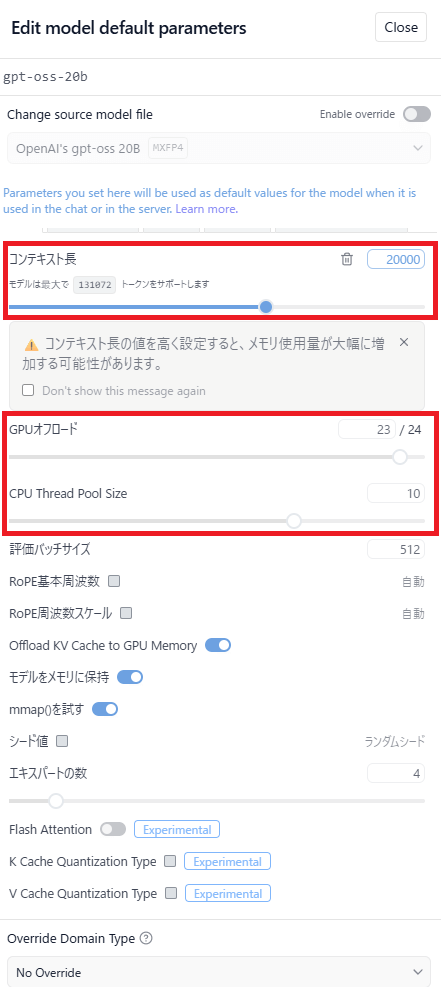
コンテキスト長の値を大きくしてみましょう
合わせて、GPUオフロードやGPU thread pool Sizeなども変更してみましょう。
もう一度、チャット画面に戻って、モデルを選択しなおすと、モデルリロードが入ります。
セットアップは以上です。
LM Studioで、他のモデル(claude・gemini)などのダウンロード
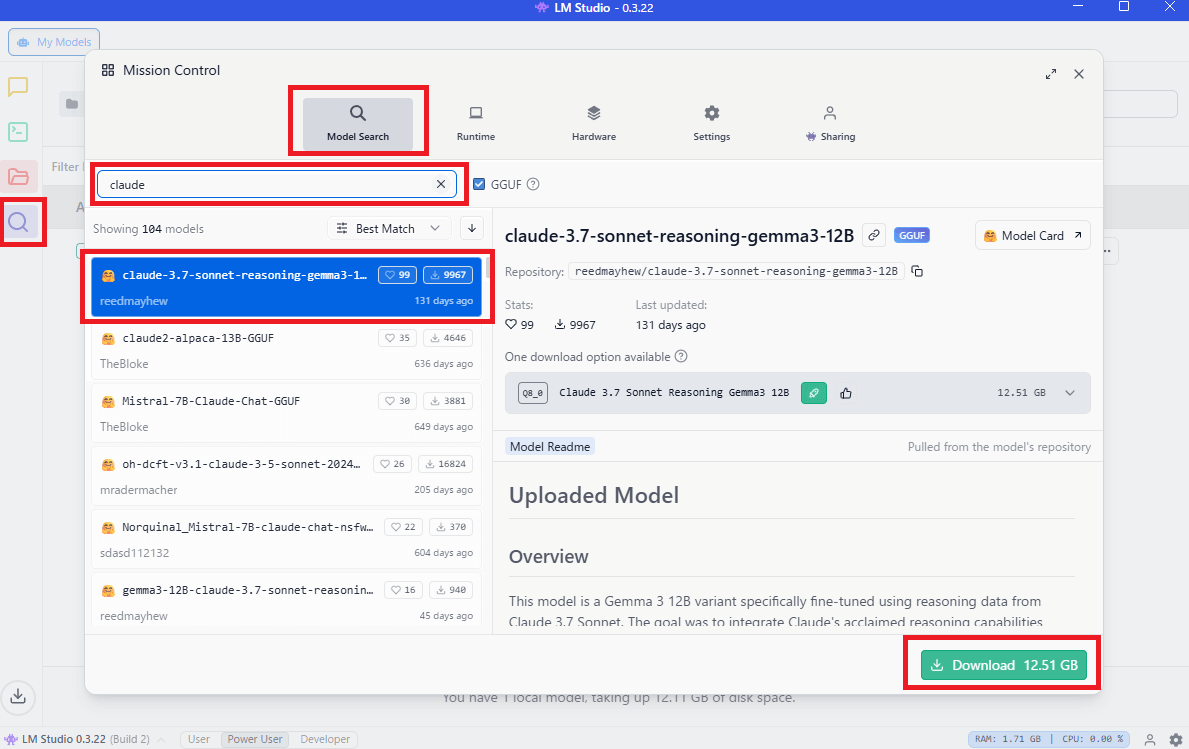
LM Studioの右側の「🔍虫眼鏡」>「Model Search」タブ>検索窓から、モデル名を入力すると、LM Studioで取り扱えるモデル一覧が出てきます。
使いたいモデルを選択して「Download」をクリックします。
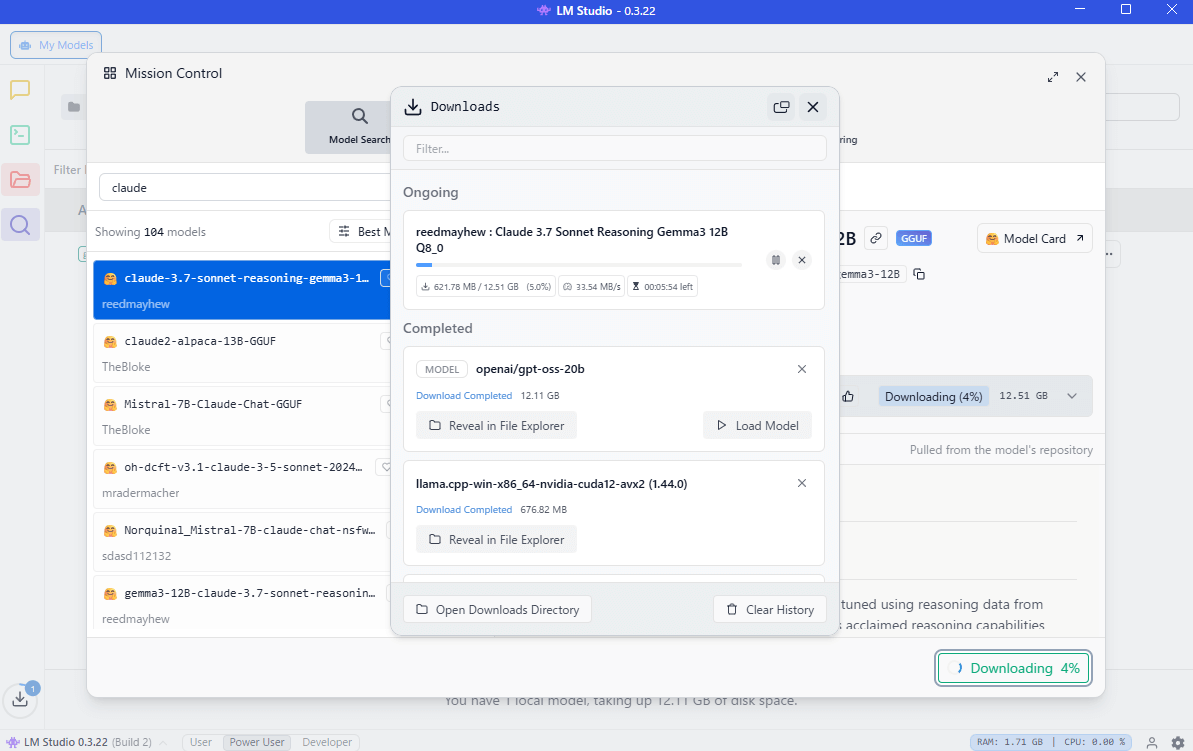
ダウンロードが始まります。
ダウンロードが終わったら、メインのチャット画面に戻ります。
上部の「読み込むモデルを選択(Ctrl+L)」をクリック
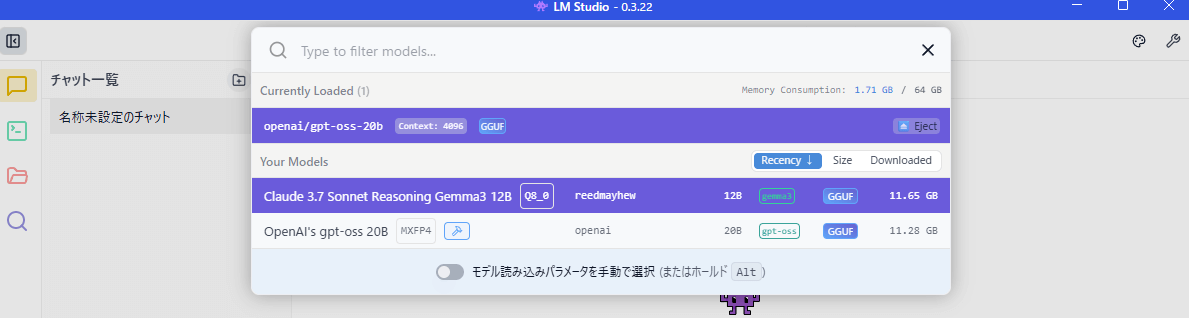
利用したいモデルを選択します
違うモデルがロードされます
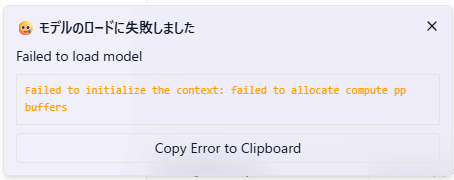
モデル切り替えで、「モデルのロードに失敗しました」と表示されるケースがあります。
モデルを利用するための必要スペックが足りないものと思われます。
※解決方法があればぜひご教示ください。
LM Studioのモデルのダウンロードフォルダ変更方法
LM Studioでは、モデルのダウンロードフォルダを変更できます。
ただし、LM Studioのインストールしたフォルダには変更できません。
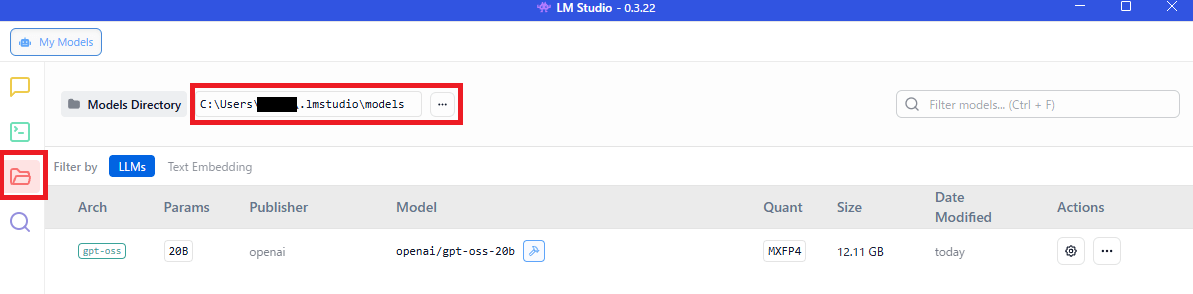
LM Studioの右側の「📁フォルダ」をクリック
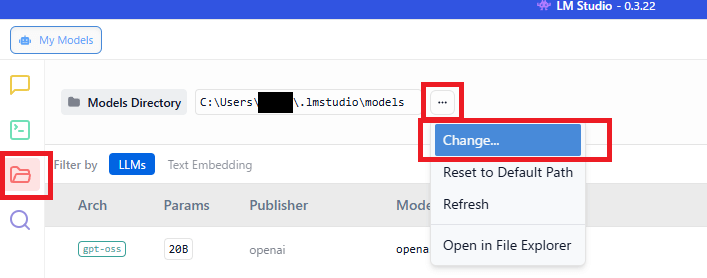
「…」をクリックして「Change」を選択

【LM Studioのモデルのデフォルトの格納場所】
C:\Users\[ユーザー名]\.lmstudio\modeles\lmstudio-community\
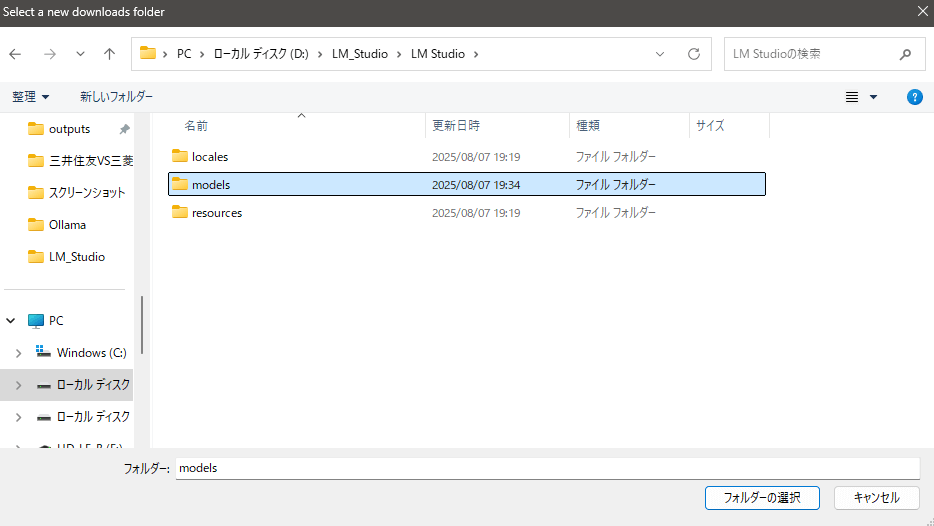
モデルの格納場所をデフォルトから変更
M Studioのインストールディレクトリ内にモデルディレクトリは設定できません。
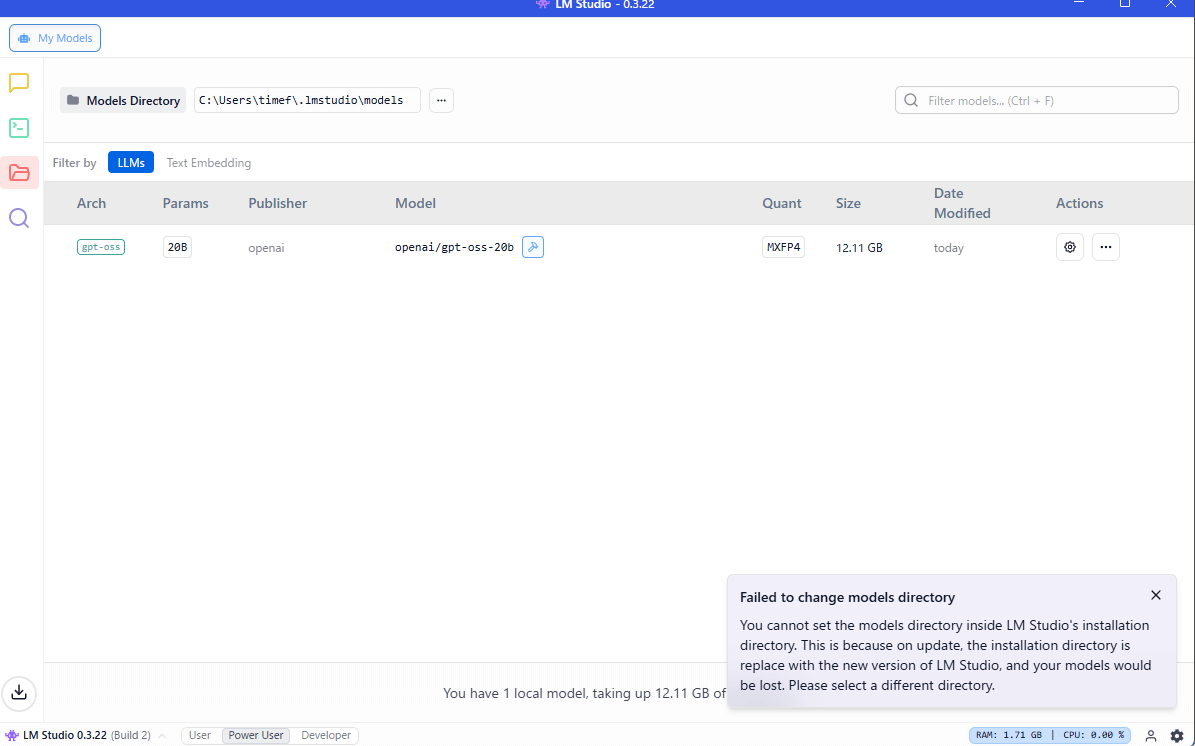
Failled to change models directory
というエラーメッセージが出て、変更できません。
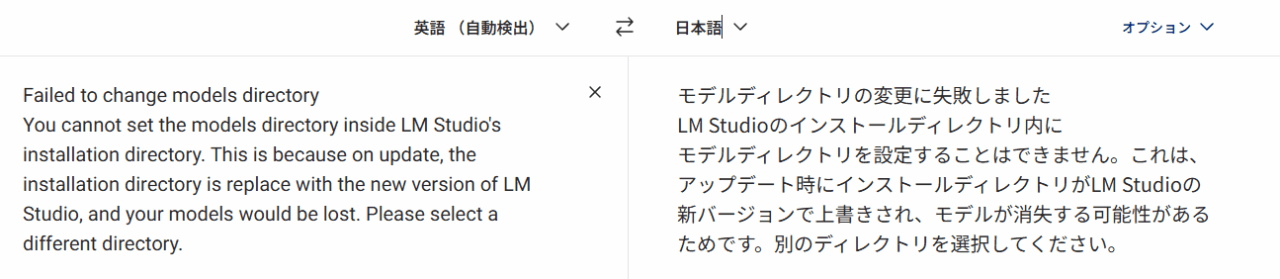
エラーメッセージを翻訳すると、以下のとおり。
モデルディレクトリの変更に失敗。LM Studioのインストールディレクトリ内にモデルディレクトリは設定できません。
LM Studio×gpt-oss-20bで消費するリソース
LM Studio×gpt-oss-20bで消費するリソースは、処理しておらず、「モデルをロードしているだけの状態」でも、消費します。
gpt-oss-20bモデルロードのみ
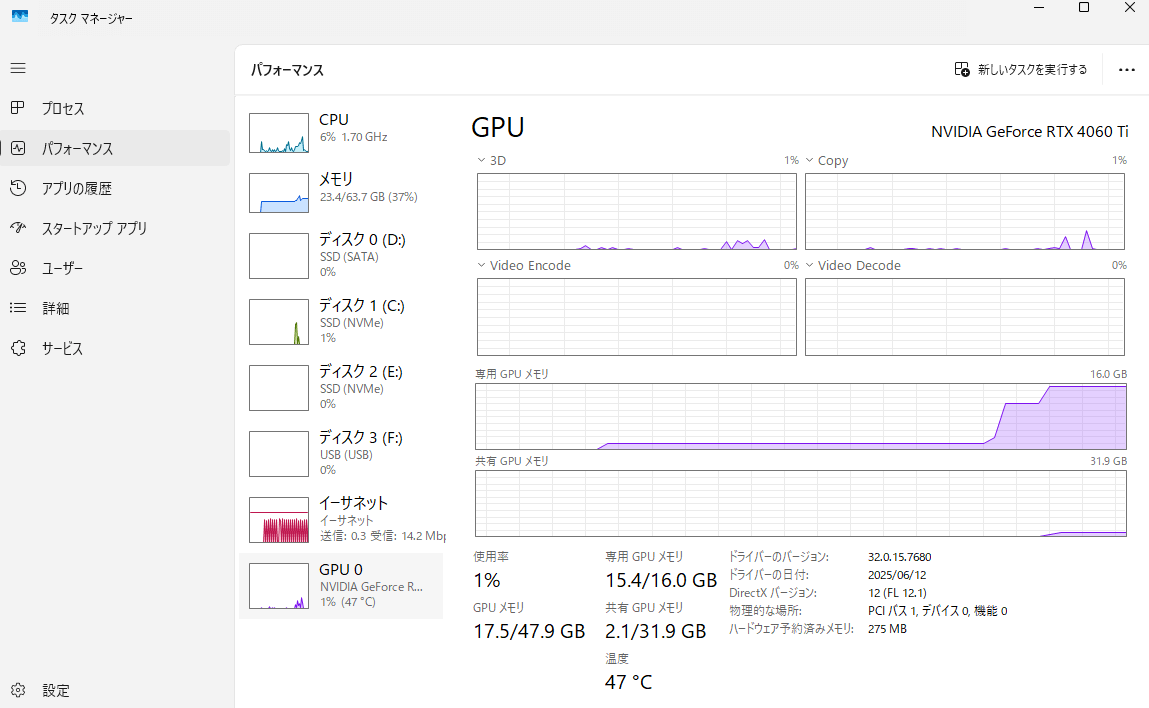
ぬくぬくの環境でLM Studioを起動し、gpt-oss-20bをロードしている状態だと、メモリは20GB程度、GPUメモリは16GBMAX張り付きです。
使っていないときは、LM Studioを消しておくか、「Eject」ボタンを押して、モデルをアンロードしておきましょう。
gpt-oss-20bで処理実行時
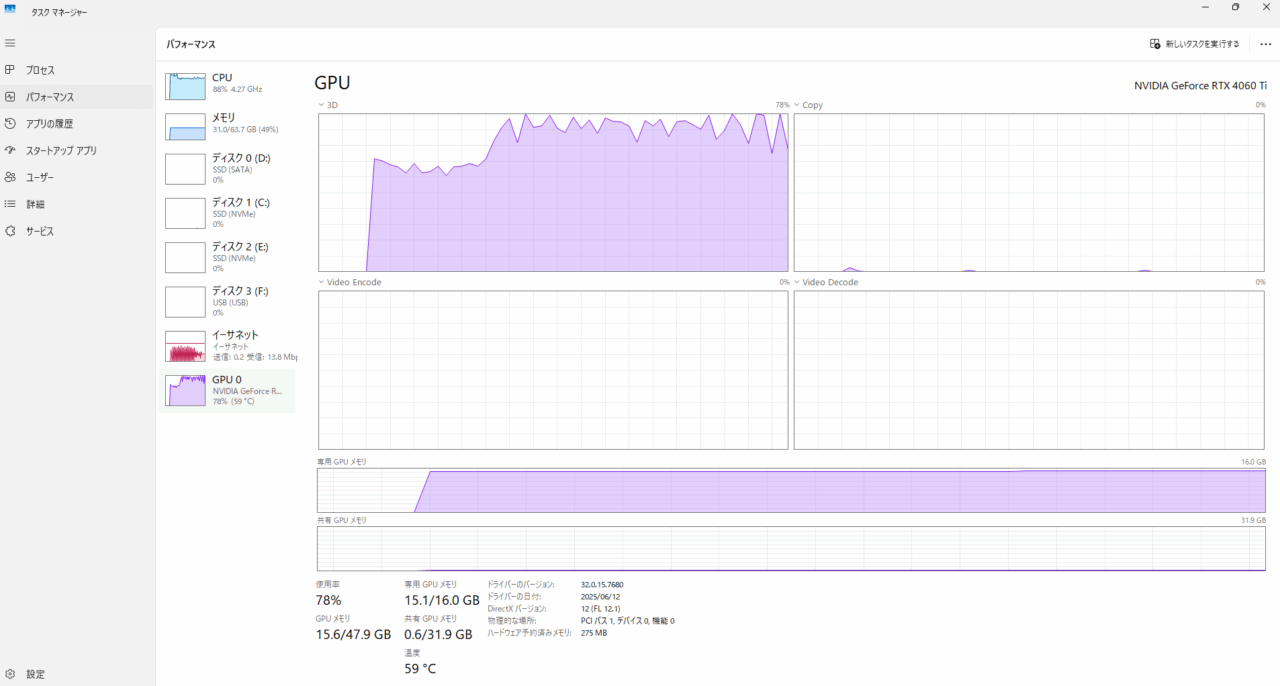
ぬくぬくの環境でLM Studioを起動し、gpt-oss-20bをロードし、何かしらチャットしている状態だと、メモリは30GB程度、GPUメモリは16GBMAX張り付きです。
以上、参考になれば幸いです。

